Transformer内部原理四部曲3D动画展示
Transformer内部原理四部曲3D动画展示
为理解Transformer的内部工作原理,从端到端(从最初的用户输入,到最终的模型输出)的角度看看数据是如何在Transformer中流转的。从宏观来看,输入数据在Transformer中经历如下四个处理阶段:

Embedding
首先,输入内容会被拆分成许多小片段(这个过程称为tokenization),这些小片段被称为词元 (Tokens)。
- 对于文本:token 通常是单词、词根、标点符号,或者其他常见的字符组合;
- 对于图像或声音:Token 则可能代表图像的一小块区域或声音的一段小片段。

每个Token会对应到一个向量上,也就是一串数字,这串数字的目的是以某种方式来表达该片段的含义。如果你把这些向量看作是在一个高维空间中的坐标,那么含义相似的词汇倾向于彼此接近的向量上。每当我说到”含义”这个词时,完全通过向量中的数字来表达。

Attention-语义交流
embedding向量间的语义交流。这些向量序列接下来会经过一个称为”Attention模块”的处理过程,使得向量能够相互”交流”并根据彼此信息更新自身的值。

例如”model”这个单词在在“machine learning model”(机器学习模型)和在“fashion model”(时尚模特)中的意思是完全不一样的。
虽然是同一个单词(token),但对应的 embedding 向量是不同的。Attention模块的作用就是要确定上下文中哪些词对更新其他词的意义有关,以及应该如何准确地更新这些含义。

Attention模块的作用就是确定上下文中哪些词之间有语义关系,以及如何准确地理解这些含义(更新相应的向量)。这里说的“含义”meaning指的是编码在向量中的信息。
MLPs-感知反馈
Attention模块让输入向量们彼此充分交换了信息(例如,单词“model”指的应该是“模特”还是“模型”), 然后,这些向量会进入第三个处理阶段:Feed-forward / MLPs。
这些向量会经过另一种处理,这个过程根据资料的不同,可能被称作多层感知机或者前馈层。
")
针对所有向量做一次性变换。这个阶段,向量不再互相”交流”,而是并行地经历同一处理。

虽然这个步骤比较难以理解,但我们会在后面讨论,这个步骤有点像对每个向量提出一系列的问题,然后根据这些问题的答案来更新向量。

这两个处理阶段的操作本质上都是海量的矩阵乘法,从宏观概述上省略了一些中间步骤的归一化细节,主要学习的是如何解读这些背后的矩阵。

重复上述Attention+Feed-forward过程组成多层网络。Transformer基本不断重复Attention和Feed-forward这两个基本结构,这两个模块的组合成为神经网络的一层。

输入向量通过attention更新彼此;
feed-forward 模块将这些更新之后的向量做统一变换,得到这一层的输出向量;
在Attention模块和多层感知机(MLP)模块之间不断切换,直到最后期望通过某种方式,使得文章的核心意义已经被完全融入到序列的最后一个向量中。
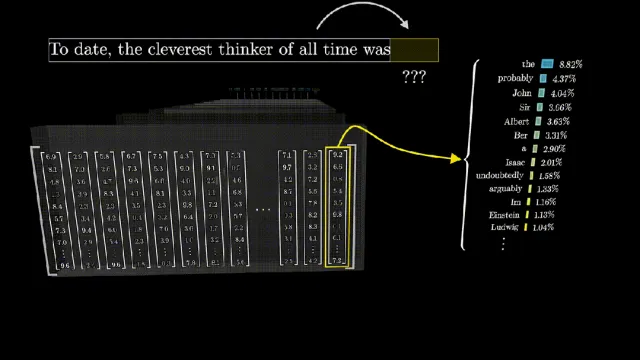
Unembedding-概率
最后一层feed-forward输出中的最后一个向量the very last vector in the sequence的备选列表及其概率, 产生一个覆盖所有可能Token的概率分布,这些Token代表的是可能接下来出现的任何小段文本,包含句子的核心意义essential meaning of the passage。对这个向量进行 unembedding 操作(也是一次性矩阵运算), 得到的就是下一个单词的备选列表及其概率。

根据一定的规则选择一个token;
注意这里不一定选概率最大的,根据工程经验,一直选概率最大的,生成的文本会比较呆板;
实际上由temperature的参数控制;
一旦拥有了这样一个工具,它可以根据一小段文本预测下一步,你就可以给它输入一些初始文本,让它不断地进行预测下一步,从概率分布中抽样,添加到现有文本,然后不断重复这个过程。了解这一点的人可能还记得,早在 ChatGPT 出现之前,GPT-3 的早期演示就是这样的,根据一段起始文本自动补全故事和文章。
Transformer内部的工作原理
有了一个这样的预测下一个单词模型,就能通过如下步骤让它生成更长的文字,非常简单:
- 将初始文本输入模型;
- 模型预测出下一个可能的单词列表及其概率,然后通过某种算法(不一定挑概率最大的) 从中选一个作为下一个单词,这个过程称为采样(sampling);
- 将新单词追加到文本结尾,然后将整个文本再次输入模型;转 2–Attention;